

Ramping up
Every topic is a bottomless rabbit hole of interestingness.
I looked at my first-draft book outline today and may have saved a life (mine). As I pick up information sources for all the specialist markets I want to dive into, it’s… a lot. In the alternative data market—this month’s focus—the overwhelm seems to be a major characteristic of the market. The outline was a good reminder that, while I want to learn from looking into these submarkets, mastering all of them was never the goal. It’s about understanding how data gets from its source to end users, and an early step is to test my assumptions about the data value chain.
Laying a foundation with the data value chain
One of the interview questions I plan to ask is about sources of information—books, newsletters, organizations, people. For each exploration of a specialist market, I want to include some pointers for where to go deeper. At the beginning, though, the main question is whether I’m working on a question that has already been answered.
Before I talked to anyone about the Data Market Study, I started collecting sources, looking for people, organizations and existing research. I’m the type to read—and follow up on—footnotes and references, so it doesn’t take long.
If the path before you is clear, you’re probably on someone else’s.
— Attributed to Joseph Campbell and Carl Jung. Tracking down sources is the short path to assuming quotable sayings are made up (Insert Lincoln Internet quote meme).
I’ve been pleased to discover books from high-profile sources that are (1) great resources that (2) don’t cover what I’m getting into. And when I do find them getting near my question, I see useful nuance on how to look things. How you think about the value chain, for example.

Different takes on the value chain
I’ve been writing here for since January, but I started collecting resources for this project years ago. Talk to enough founders about their software startups, and you notice trends. But as someone who once reinvented an established IT framework and thought it was a new idea, I want to see what else is out there.
Starting with the (very) high-level view, we have the DIKW pyramid (data – information – knowledge – wisdom) that’s been around forever. From this starting point, we get the idea of a lift from raw data to actionable insight, which informs my view of the work required along the way.
George Sarmonikas lays out a similar progression with his version of the data valuation chain from data generation to value. It doesn’t tell us a lot about the role of companies in a supply network, but it helps to understand what’s happening to the data as it progresses toward usefulness.
Before pointing out that selling shovels is still a winning strategy, Louis-David Benyayer (Datanomics) lays out a data value chain with four major components:
Generation: activities and assets necessary to capture and record data
Collection: activities and assets to collect, validate and store data
Analysis: activities and assets to analyse and generate insights
Exchange: activities to expose outputs internally and externally
The EUSPA EO and GNSS Market Report breaks it out further, focusing on roles instead of activities. This is getting closer to the supply network view:
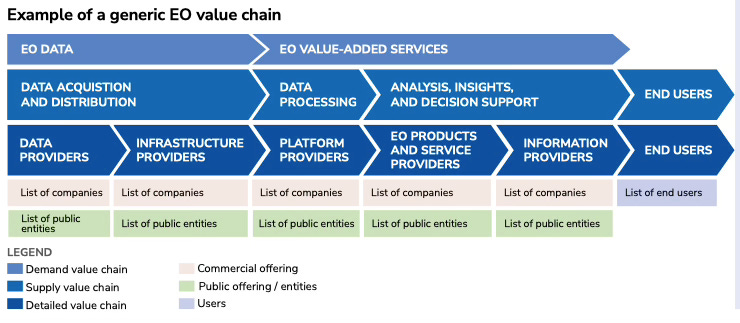
Data providers: Providers of unprocessed or pre-processed EO data from multiple sources
Infrastructure providers: Providers of various types of computing infrastructure upon which EO data can be accessed, stored, distributed or manipulated
Platform providers: Providers of online platforms and/or digital services, through which users can utilise tools and capabilities to analyse EO data, develop algorithms and build applications
EO products and service providers: Providers of products (e.g. land cover classifications) or services (e.g. ground Climate, Environment motion monitoring) that make full use of EO data and processing capabilities and Biodiversity offered by data and platform providers
Information providers: Providers of sector-specific information that incorporates EO data along with non-EO data
End Users: Final users benefitting in their decision making or operations from the solutions offered by EO services and/or information providers
Data is, or is not, the new oil, depending on which point you want to make, but the metaphor has value-chain implications. Alexander Denev and Saeed Amen, in The Book of Alternative Data, expand on Rob Passarella’s comparison of data to oil in upstream, midstream and downstream sectors. Like oil, data starts as crude, unrefined potential, and as it moves downstream, it passes through a series of specialist firms that refine it into something of use for end users.
In Infonomics, Doug Laney focuses primarily on the interests of companies whose primary business is not information, and most of that is not about selling data. His points on the data value chain are mostly about how existing frameworks from supply-chain management and library science might inform the development of new management and accounting practices for valuing and tracking data assets.
Data is Everybody’s Business is also all about data monetization in companies not primarily in the information business. I don’t think the authors even mention the buyers in the data sales scenario, which is decidedly secondary to using data to improve companies’ existing businesses. It’s so nice to be able to recommend these last two books as must-reads for their intended audience that don’t get into the topic I’m working on.
So we have some high-level metaphors and some practical business priorities. So far, I haven’t found anyone else who’s particularly looking at the supply network itself.
Where it gets complicated
As far as they go, these models—especially the oil market analogies—map pretty well to what I’ve seen of companies collecting, processing, analyzing, and presenting data. Where we’re going with this is to move beyond the conceptual framework to an understanding of the roles and strategies real companies deploy in the market, on the way to a view of the supply network itself. I expect it to be a hairball—but one with underlying patterns we can understand.
Inspiration
Marshall Kirkpatrick highlighted two current projects: AI Time to Impact and Sunflower News (climate).
Discovery
Going down the Substack rabbit hole on alt data—Asymmetric Advantage, The Data Observatory, The Data Score, Alt Data Weekly. And everyone has their own list of more.
TBR
Capitalism Without Capital – I expect to see a lot of common ground with Laney’s attention to data assets in GAAP (not assets at all), but I’m curious where the more academic take leads.
Means of Control: How the Hidden Alliance of Tech and Government Is Creating a New American Surveillance State – All this data looks very different if you approach it from the side of the people it represents.
Hyperobjects: Philosophy and Ecology after the End of the World – Read a book about risk, uncertainty and Taleb, consider yourself lucky it only added one more book to TBR.
Squirrel!
Cars need physical controls.
We’re going to see more discussion of geoengineering. Tomas takes deeper dives than most.
Thank you for the mention. Happy to speak when you are ready